Monthly Archives: May 2013
1-click Random Decision Forests
The Official Blog of BigML.com
One of the pitfalls of machine learning is that creating a single predictive model has the potential to overfit your data. That is, the performance on your training data might be very good, but the model does not generalize well to new data. Ensemble learning of decision trees, also referred to as forests or simply ensembles, is a tried-and-true technique for reducing the error of single machine-learned models. By learning multiple models over different subsamples of your data and taking a majority vote at prediction time, the risk of overfitting a single model to all of the data is mitigated. You can read more about this in our previous post.
Early this year, we showed how BigML ensembles outperform their solo counterparts and even beat other machine learning services. However, up until now creating ensembles with BigML has only been available via our API. We are excited to announce that ensembles are now available via our…
View original post 869 more words
If you’re disappointed with big data, you’re not paying attention
There has been a backlash lately against big data. From O’Reilly Media to the New Yorker, from Nassim Taleb to Kate Crawford, everyone is treating big data like a piñata. Gartner has dropped it into the “trough of disillusionment.” I call B.S. on all of it.
It might be provocative to call into question one of the hottest tech movements in generations, but it’s not really fair. That’s because how companies and people benefit from big data, data science or whatever else they choose to call the movement toward a data-centric world is directly related to what they expect going in. Arguing that big data isn’t all it’s cracked up to be is a strawman, pure and simple — because no one should think it’s magic to begin with.
Correlation versus causation versus “what’s good enough for the job”
One of the biggest complaints — or, in some…
View original post 1,242 more words
Why new tech palaces may signal impending doom for Apple, Amazon, Google and Facebook
Man uses skateboard to fend off large cougar after surprise attack in Banff national park
The Social vs. Interest Graph
Your Future On Stack Overflow
I recently spent a while working on a pretty fun problem over at Stack Exchange: predicting what tags you’re going to be active answering in.
Confirmed some suspicions, learned some lessons, got about a 10% improvement on answer posting from the homepage (which I’m choosing to interpret as better surfacing of unanswered questions).
Good times.
Why do we care?
Stack Overflow has had the curious problem of being way too popular for a while now. So many new questions are asked, new answers posted, and old posts updated that the old “what’s active” homepage would cover maybe the last 10 minutes. We addressed this years ago by replacing the homepage with the interesting tab, which gives everyone a customized view of stuff to answer.
The interesting algorithm (while kind of magic) has worked pretty well, but the bit where we take your top tags has always seemed a…
View original post 1,645 more words
42
In The Hitchhiker’s Guide to the Galaxy by Douglas Adams, the number 42 is the “Answer to the Ultimate Question of Life, the Universe, and Everything”. But he didn’t say what the question was!
Since today is Towel Day, let me reveal that now.
If you try to get several regular polygons to meet snugly at a point in the plane, what’s the most sides any of the polygons can have? The answer is 42.
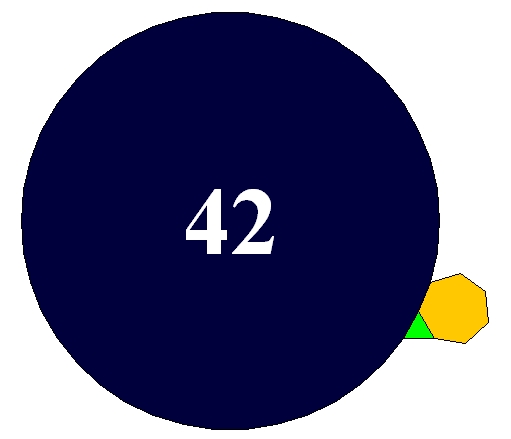
The picture shows an equilateral triangle, a regular heptagon and a regular 42-gon meeting snugly at a point. If you do the math, you’ll see the reason this works is that
$latex \displaystyle{ \frac{1}{3} + \frac{1}{7} + \frac{1}{42} = \frac{1}{2} } $
There are actually 10 solutions of
$latex \displaystyle{ \frac{1}{p} + \frac{1}{q} + \frac{1}{r} = \frac{1}{2} } $
with $latex p \le q \le r,$ and each of them gives a way for…
View original post 1,095 more words
